The Electric Monastery
Don't trust AI to tell you what is true
There is a strange contradiction at the heart of our attitude to Wikipedia and the use it is put to by tech companies. On the one hand, everybody knows that Wikipedia is not a reliable source, including Wikipedians. It is against policy to cite a Wikipedia article for a claim on another Wikipedia article, because - as user-generated content collated by self-organising volunteers of wildly variable levels of competence and personal or political bias - the information on any article is fundamentally untrustworthy.
On the other, everybody relies on Wikipedia, it is a substantial part of AI training sets, it appears top of search results, and occupies a privileged position in the technology ecosystem. It is simultaneously too unreliable for its own use, but “good enough” to provide a single source of truth for the vast majority of questions humanity poses to search engines and AI.
So all that being said, Grokipedia is a terrible idea.
For those that are blissfully ignorant, Grokipedia is Elon Musk’s answer to the bias of the average Wikipedia editor when it comes to contentious political issues, in the form of an AI-generated encyclopedia tuned to produce results more pleasing to Musk’s political sensibilities. Rather than address the issues with Wikipedia and its position in our technopoly, Grokipedia seems to largely plagiarise it while adding a whole new layer of distrust, unreliability, and political polarisation.
In Dirk Gently’s Holistic Detective Agency, author Douglas Adams - in yet another moment of bleakly humorous prescience - came up with the idea of the Electric Monk. This was a labour-saving device whose purpose was to believe things, so that the owner didn’t have to:
“The Electric Monk was a labour-saving device, like a dishwasher or a video recorder. Dishwashers washed tedious dishes for you, thus saving you the bother of washing them yourself, video recorders watched tedious television for you, thus saving you the bother of looking at it yourself; Electric Monks believed things for you, thus saving you what was becoming an increasingly onerous task, that of believing all the things the world expected you to believe.” - Douglas Adams, Dirk Gently’s Holistic Detective Agency
As we become ever more rabid consumers of new information, craving constant novelty in our newsfeeds, we are losing the ability to know what to believe - we simply have too many new and conflicting events to spend the time constructing an informed opinion on everything overwhelming our senses. This is the position AI is fighting to occupy in our technological infrastructure, whether in the form of Grokipedia or Google’s AI search results or AI-powered news summaries - ask a question, and get told what to believe. Collapsing the complexity of subjects where there may not be a singular answer into a readily accepted simplistic response delivered with the cold authority of the machine.
This is a huge missed opportunity. Rather than using AI to replace human struggles to discern truth with thought-terminating slop, we could instead try and use AI as a different sort of labour-saving device, to expose the complexity hidden underneath the simplest of statements.
What if, rather than wasting everybody’s time on culture war dick-waving competitions, these vast engineering resources and limitless budgets were poured in to making tools to allow anybody to visualise, connect and judge competing sources of information for ourselves? Sure, Wikipedia is ostensibly transparent, but who can be bothered to trawl through the sources and page history to see how the sausage is actually made and decide whether a particular paragraph is even remotely trustworthy? Who even has the time? What if editors and readers alike were given the ability to verify claims and weight sources and consider uncited sources directly in Wikipedia, providing a layer of accountability on top of the opaque decision-making process?
Wikipedia content is governed by rules - policies about what should be cited, how it should be balanced, what tone to strike and so on - which have been created by community consensus. However, having rules is different to following them, and on Wikipedia the application of policy is also matter of consensus. Humans are fallible, consensus can arrive at poor decisions for all sorts of interpersonal reasons, and as such policy is not always applied consistently.
This is all largely invisible to the casual reader. There is technically an audit trail and talk page discussions, but deciding whether or not the citations justify the text or whether the many arcane policies and guidelines have been correctly applied is not something the vast majority of readers have the time or even the ability to do. No passing user reading a snippet of a Wikipedia article from the top of their search results is going to have much of an idea of how the content on a page has been arrived at and whether it is any way compliant with policy, or the article’s citations.
AI, on the other hand, can do exactly this. Rather than Grokipedia’s focus on telling you a competing version of what is true and synthesising a singular narrative to stack up against Wikipedia, why not analyse the text of a Wikipedia article and its sources, apply Wikipedia’s policies to it, and see to what degree the citations are accurate and the rules have been followed? And why not provide this both as a tool for editors to be able to check their work, and to readers to make more visible the shortcomings of any articles?

I’ve been building a tool that can do this out of my own personal interest. It works by taking an article and breaking it into paragraphs, along with their references, footnotes and any other cited works. It then sends each of these to an AI along with a prompt requiring it to verify the supplied text against the cited references, and asks for the text to be checked against Wikipedia policies and guidance. Does the passage contain any original research? Are medical claims compliant with policy on medically reliable sources? Is everything verifiable and written from a neutral point of view? And so on.
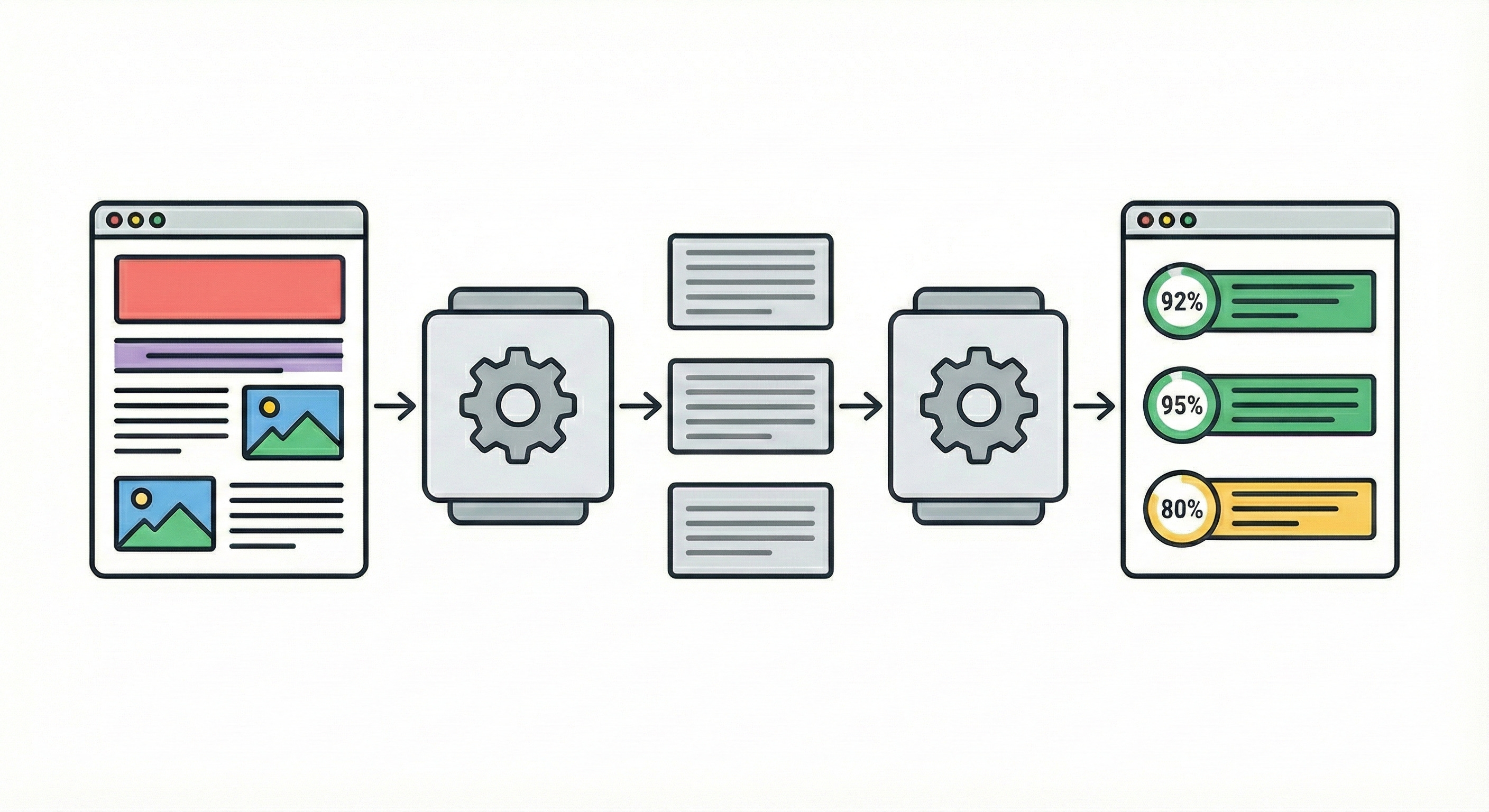
The end result of this is to produce a textual analysis of the paragraph and its policy compliance, along with a numeric score out of 100. The opening section is then separately analysed in conjunction with all of these analyses to verify that the article lede correctly summarises the article itself (per the guidance that the lede follows the body), and finally an overall score for the article as a whole. This is all then combined onto a page containing all of the text and citations of the original article, with a paragraph-by-paragraph score and an analysis of each part that anybody can read.
To illustrate, here is an AI analysis of the Wikipedia article on HMAS Emu, an Australian tugboat. I selected this simply because it recently appeared on the “Did You Know?” section of the Wikipedia homepage, with the note that it “once rescued a cigarette-smoking chimpanzee and his magician owner”.:
This article is short, politically uncontroversial, and reasonably new, and according to a paragraph-by-paragraph AI analysis the text itself is mostly good, with every section scoring highly.
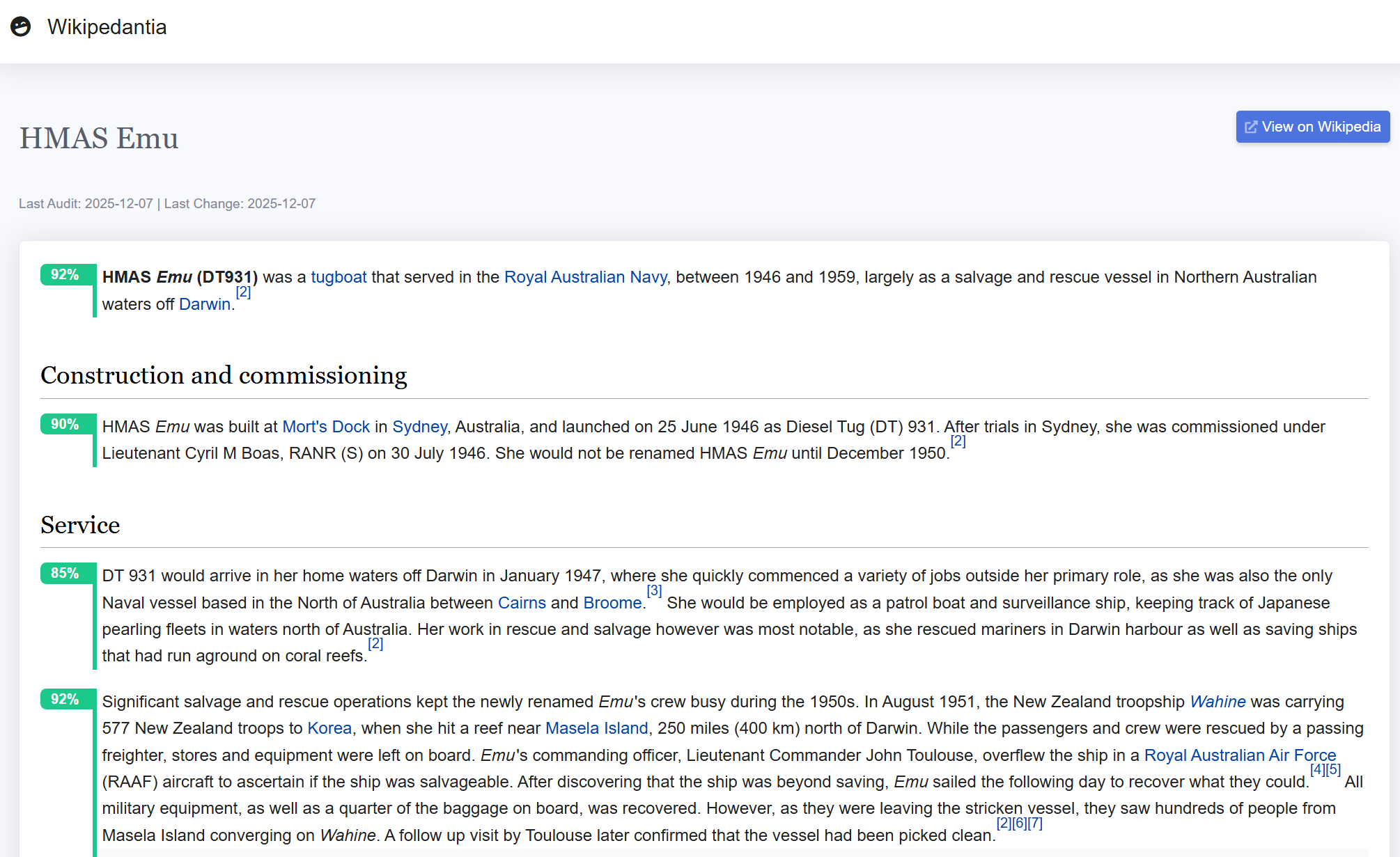
However, while reading the results, I found that the AI analysis did turn up something interesting in this paragraph:
In August 1951, the New Zealand troopship Wahine was carrying 577 New Zealand troops to Korea, when she hit a reef near Masela Island, 250 miles (400 km) north of Darwin.
Running an automated analysis over this text and its citations produced the following assessment:
The passage is largely supported by the cited contemporary newspapers and the Royal Australian Navy Sea Power Centre history, but one factual detail is not supported: the troop count (given as 577) does not match the cited sources, which report 575.
According to this, the article misstates the number of troops on board the TSS Wahine when it ran aground in August 1951. This might seem inconsequential to most, but bear in mind that Wikipedia is entirely dependent on the goodwill of people who care enough about minutae like this, and everything is important to somebody. I’m sure this would be of great importance to the two people who were - or were not -on board at the time.
So - is this true? Well, there are three citations for the claim.
The first is an August 16th 1951 report of the sinking, which says:
The 4,436 ton New Zealand troopship “Wahine,” carrying 575 New Zealand troop replacements for Korea, was 23 miles off the usual channel route when she grounded on a reef near Masela Island early this morning.
The second is a contemporary report of the looting of the vessel, which says:
The Wahine, carrying 575 NZA troops to Korea, ran aground on August 15.
The third is an archive of the maritime record of the Wahine which only says:
1951 August 2 After minor alterations had been effected she departed from Wellington under the command of Captain F. D. Johnson, carrying 577 troops and a crew of 80. Following a call at Cairns, she proceeded to Darwin where she refuelled, leaving there on the 14th of August.
As far as I can tell, the AI assessment is absolutely right - the two contemporary sources say there were 575 troops on board when it ran aground, and the maritime record says only that it was carrying 577 when it departed Wellington two weeks earlier, with a stop off at Cairns in between.
Compare this to the article on the TSS Wahine, which says only that she “left Wellington carrying 577 troops” and is silent on how many were on board when she ran aground.
In my opinion, this is exactly the sort of thing AI can be useful for, namely as a human-directed, labour saving tool applying defined rules to rapidly compare text to sources it has been provided with. Given those three sources, and that text, and Wikipedia’s extensive rules on sourcing, the most we can say is that - according to those sources - there were 577 troops on board when it left Wellington, and 575 on board when it ran aground two weeks later. It is absolutely feasible to have an automated tool flagging up potential errors to editors and readers alike, and in my opinion this is the kind of endeavour that could benefit Wikipedia as a whole if integrated both into the editing process and into the reader’s view of a page.
That being said, the current generation of AI isn’t quite up to doing this entirely automatically. Aside from the problem of the sheer length of some documents or the problems of automating access to paywalled sources or printed books, the main stumbling block is that AI doesn’t know what it doesn’t know. The omission of potentially contradictory references is as significant a problem as misrepresenting the ones that are actually used, so while an AI might score a paragraph highly based on the sources it does cite, when provided with additional ones that have not been cited it can correct and scores low. For now, deciding what has been left out is a matter of human judgement, and any output is highly susceptible to reflecting the biases of whoever asked the question. It is tempting to reshape the prompts and get exactly the results we expect - pages can score high or low depending on the precise wording of the question and the context given, dressed up with the flattering illusion of objectivity we project onto machine-generated text. Checking facts on a low consequence page like HMS Emu is a long way from verifying the neutrality and sourcing on a hot mess battleground such as “Political views of JK Rowling”.
Flawed as it is, I still believe an approach like this is something that would be far more valuable than building a differently-biased spin on top of plagiarised Wikipedia articles, like Grokipedia.
Wikipedia assumes that it on average improves over time, that if the majority of information there is good then any errors will average out, and every technological service that builds upon this assumption compounds it. Tech companies like Google have become so used to operating at scale that it is easy for them to assume an acceptable level of error in search results, and consequently an acceptable level of error in AI-generated responses. Sure, they might not always hit the mark, but on average responses are useful and relevant, as judged by users’ continued attention and usage of the service.
But the average of wrong is not truth.
There is scope here to use AI to make the context surrounding information visible, and all its flaws instantly available for anyone to judge. Instead however, vast amounts of computing power is being given over to further obscuring this, with tech companies endlessly refining their Electric Monks, all deferentially wired up to Wikipedia, all fighting over which brotherhood will be dominant, which monastery will receive humanity’s tithe in return for freeing us from the tiresome burden having to know what to believe.